目录:
一、联合查询
1、联合查询
联合查询:union,是指将多个查询结果合并成一个结果显示
联合查询是针对查询结果的合并(多条select语句合并)
联合查询要求:联合查询是结果联合显示
- 多个联合查询的字段结果数量一致
- 联合查询的字段来源于第一个查询语句的字段
查询选项:union默认是去重的,想要保留全部查询结果,需要使用union all
- all:保留所有记录
- distinct:保留去重记录(默认)
select 查询[字段名字]
union 查询选项
select 查询
...【例】创建一个表同t_40,并插入数据,联合查询
create table t_42 like t_40;
insert into t_42 values(null,'犬夜叉','男',200,'神妖1班'),
(null,'日暮戈薇','女',16,'现代1班'),
(null,'桔梗','女',88,'法师1班'),
(null,'弥勒','男',28,'法师2班'),
(null,'珊瑚','女',20,'法师2班'),
(null,'七宝','保密',5,'宠物1班'),
(null,'杀生丸','男',220,'神妖1班'),
(null,'铃','女',4,'现代1班'),
(null,'钢牙','男',68,'神妖1班'),
(null,'奈落','男',255,'神妖1班'),
(null,'神乐','女',15,'神妖2班');使用联合查询将两张表的数据拼接到一起显示
select * from t_40 union select * from t_42;
# 联合查询选项默认是distinct
select * from t_40 union all select * from t_42;联合查询不要求字段类型一致,只对数量要求一致,而且字段与第一条查询语句相关
select name from t_40 union all select age from t_40;注意:如果数据不能对应,那么查询没有意义
如果使用where对数据进行筛选,where针对的是select指令,而不是针对union结果
select * from t_40
union all
select * from t_42 where gender = '女';注意:where只针对第二条select有效;若要全部有效,需要select都使用where
2、联合查询排序
联合查询排序:针对联合查询的结果进行排序
order by本身是对内存结果进行排序,union的优先级高于order by,所以order by默认是对union结果进行排序
如果想要对单独select的结果进行排序,需要两个步骤
- 将需要排序的select指令进行括号包裹(括号里使用order by)
- order by必须配合limit才能生效(limit一个足够大的数值即可)
【例】将t_40和t_42表的结果使用年龄降序排序
select * from t_40
union all
select * from t_42
order by age desc;【例】t_40表按年龄降序排序,t_42表按年龄升序排序
# 无效方式
(select * from t_40 order by age desc)
union
(select * from t_42 order by age);
# 正确方式
(select * from t_40 order by age desc limit 99999)
union
(select * from t_42 order by age limit 99999);二、连接查询
连接查询:join,将两张表依据某个条件进行数据拼接
join左右各一张表:join关键字左边的表叫左表,右边的表叫右表
连接查询的结果都是记录会保留左右表的所有字段(字段拼接)
- 具体字段数据依据查询需求确定
- 表字段冲突需要使用表别名和字段别名区分
不同的连表有不同的连接方式,对于结果的处理也不尽相同
连接查询不限定表的数量,可以进行多表连接,只是表的连接需要一个一个的连(A join B join C ...)
1、交叉连接
交叉连接:cross join,不需要连接条件的连接
交叉连接产生的结果就是笛卡尔积
- 左表的每一条记录都会与右表的所有记录连接并保留
交叉连接没有实际数据价值,只是丰富了连接查询的完整性
【例】交叉连接t_41和t_42表
select * from t_41 cross join t_42;这种连接无意义,尽量避免使用
2、内连接
内连接:[inner] join,将两张表根据指定的条件连接起来,严格连接
内连接是将一张表的每一条记录去另外一张表根据条件匹配
- 匹配成功:保留连接的数据
- 匹配失败:都不保留
内连接可以没有on条件,那么得到的结果就是交叉连接(笛卡尔积),无意义
内连接的on关键字可以换成where,结果是一样(但是不建议使用)
左表 join 右表 on 连接条件【例】设计学生表和专业表,获取已经选择了专业的学生信息,包括所选专业
# 学生表
create table t_43(
id int primary key auto_increment,
name varchar(50) not null,
course_no int
)charset utf8;
insert into t_43 values(null,'Student1',1),
(null,'Student2',1),
(null,'Student3',2),
(null,'Student4',3),
(null,'Student5',1),
(null,'Student6',default);
# 专业表
create table t_44(
id int primary key auto_increment,
name varchar(50) not null unique
)charset utf8;
insert into t_44 values(null,'Computer'),(null,'Software'),(null,'Network');学生和专业在两个表中,所以需要连表
学生必须有专业,而专业也必须存在,所以是内连接
连接条件:专业编号
两张表有两个字段冲突:id、name
select t_43.*, t_44.name as course_name from t_43 join t_44 on t_43.course_no = t_44.id;
# 使用别名
select s.*, c.name as c_name from t_43 as s join t_44 c on s.course_no = c.id;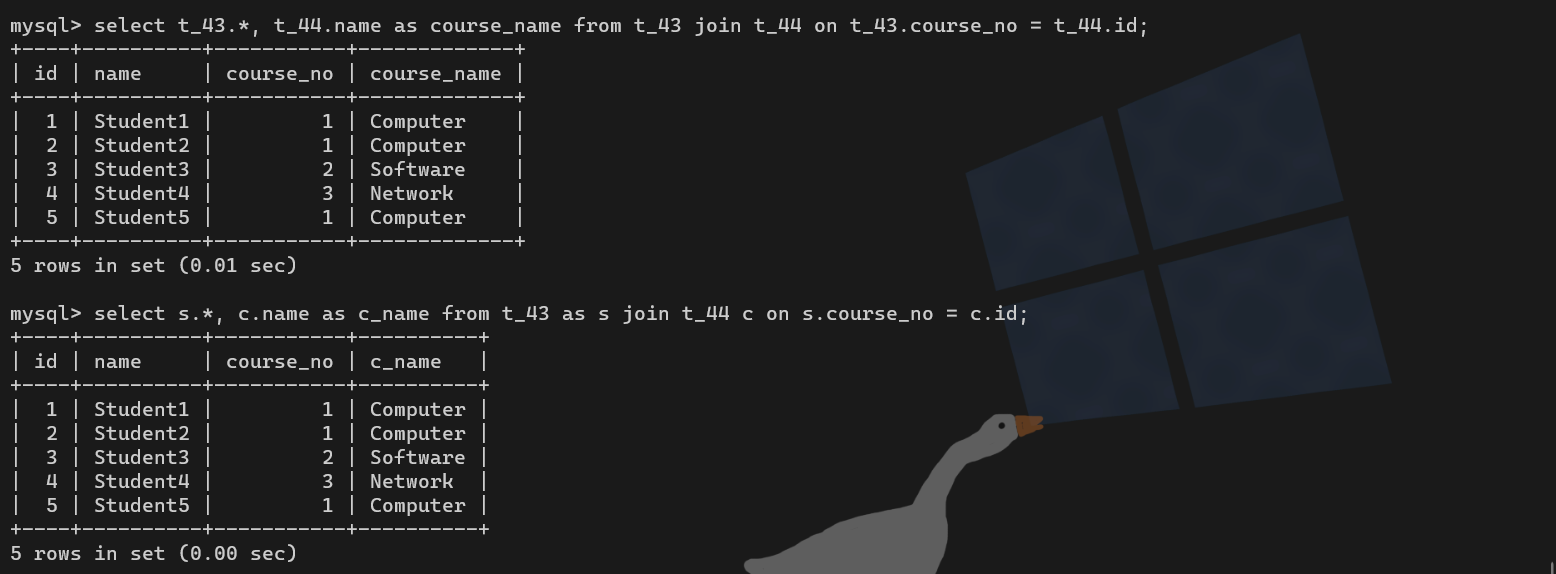
字段冲突的话在MySQL里倒是不影响,只是会同时存在,但是后续其他地方使用就不方便了
3、外连接
外连接:outer join,是一种不严格的连接方式
外连接分为两种
- 左外连接(左连接):left join
- 右外连接(右连接):right join
外连接有主表和从表之分
- 左连接:左表为主表
- 右连接:右表为主表
外连接是将主表的记录去匹配从表的记录
- 匹配成功保留
- 匹配失败(全表):也保留,只是从表字段置空
外连接不论是左连接还是右连接,字段的顺序不影响,都是先显示左表数据,后显示右表数据
外连接必须使用on作为连接条件(不能没有或者使用where替代)
外连接与内连接的区别在于数据匹配失败的时候,外连接会保留一条记录
- 主表数据保留
- 从表数据置空
【例】查出所有的学生信息,包括所在班级(左连接)
select s.*, c.name Course_Name from t_43 s left join t_44 c on s.course_no = c.id;【例】查出所有班级里的所有学生(右连接)
select s.*, c.name Course_Name from t_43 s right join t_44 c on s.course_no = c.id;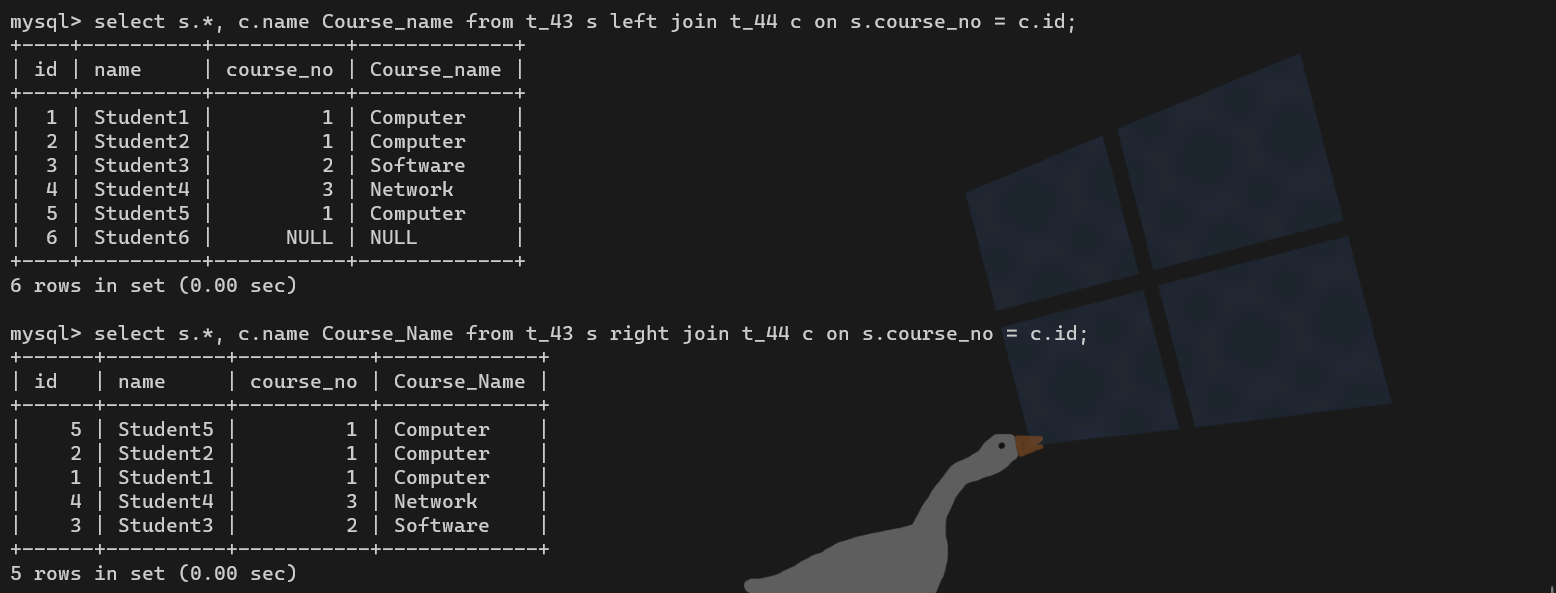
4、自然连接
自然连接:natural join,是一种自动寻找连接条件的连接查询
自然连接包含自然内连接和自然外连接
- 自然内连接:natural join
- 自然外连接:natural left/right join
自然连接条件匹配模式:自动寻找相同字段名作为连接条件(字段名相同)
自然连接本身不是一种特别连接,是基于内连接、外连接和交叉连接实现自动条件匹配而已
- 没有条件(没有同名字段):交叉连接
- 有条件:内连接/外连接(看关键字使用)
自然连接使用较少,因为一般情况下表的设计很难做到完全标准或者不会出现无关同名字段
【例】自然连接t_43和t_44表
select * from t_43 natural join t_44;【例】
create table t_45(
s_id int primary key auto_increment,
s_name varchar(50) not null,
c_id int comment '课程id'
)charset utf8;
insert into t_45 select * from t_43;
create table t_46(
c_id int primary key auto_increment,
c_name varchar(50) not null unique
)charset utf8;
insert into t_46 select * from t_44;
# 自然连接:条件只有一个相同的c_id
select * from t_45 natural join t_46;
5、using 关键字
using关键字:连接查询时如果是同名字段作为连接条件,using可以代替on出现(比on更好)
using是针对同名字段(using(id) === A.id = B.id)
using关键字使用后会自动合并对应字段为一个
using可以同时使用多个字段作为条件
【例】查询t_45中所有的学生信息,包括所在班级名字
select s.*, c.c_name from t_45 s left join t_46 c using(c_id);
select * from t_45 s left join t_46 c using(c_id);三、子查询
子查询:sub query,通过select查询结果当做另外一条select查询的条件或者数据源
【例】想查出某个专业的所有学生信息
select * from t_45 where c_id = (
select c_id from t_46 where c_name = '专业名称'
);1、标量子查询
标量子查询:子查询返回的结果是一行一列,一个值
标量子查询是用来做其他查询的条件的,通常用简单比较符号来制作条件的
【例】获取computer专业的所有学生
select * from t_45 where c_id = (
select c_id from t_46 where c_name = 'Computer'
);2、 列子查询
列子查询:子查询返回的结果是一列多行
列子查询通常是作为外部主查询的条件,而且是使用in来进行判定
【例】获取所有有学生的班级信息
select * from t_46 where c_id in (
select distinct c_id from t_45 where c_id is not null
);3、行子查询
行子查询:子查询返回的结果是一行多列
行子查询需要条件中构造行元素(多个字段组成查询匹配条件)
- (元素1,元素2,..元素N)
行子查询通常也是用来作为主查询的结果条件
【例】获取学生表中性别和年龄都与弥勒相同的学生信息
# 方法一:两个标量子查询
select * from t_40 where gender = (
select gender from t_42 where name = '弥勒'
) and age = (
select age from t_42 where name = '弥勒'
);
# 方法二:构造条件行元素(gender, age)
select * from t_40 where (gender, age) = (
select gender, age from t_42 where name = '弥勒'
);4、表子查询
表子查询:子查询返回的结果是多行多列(二维表)
表子查询多出现在from之后当做数据源(from子查询)
表子查询通常是为了想对数据进行一次加工处理,然后再交给外部进行二次加工处理
【例】获取学生表中每个班级里年龄最大的学生信息(姓名、年龄、班级名字),然后按年龄降序排序显示
# 尝试直接解决
select any_value(name),max(age) m_age,class_name from t_42 group by class_name order by m_age desc;分组统计中any_value取的是分组后的第一条记录数据(犬夜叉),而我们要的是最大
解决方案:要是在分组之前将所有班级里的学生本身是降序排序,那么分组的第一条数据就是满足条件的数据。但是问题是:order by必须出现在 group by之后,如何解决?
# order by必须在group by之前解决:就要想办法让order by在group by之前而且不在同一条select指令中(同一条无解)
# 必须使用子查询解决在不用SQL中的问题,而子查询的结果应该是全部记录信息,所以应该是表子查询,而且是数据源
select any_value(name),max(age),class_name from (
select name, age, class_name from t_42 order by age desc
) as t group by class_name;依然无效:原因是MySQL7以后若要子查询中的order by生效,需要像联合查询那样,让子查询带上limit
select any_value(name), max(age), class_name from (
select name, age, class_name from t_42 order by age desc limit 99999
) as t group by class_name;因为order by在子查询的时候已经对结果进行过排序了,所以分组统计后最终结果也就不用再进行排序了,如果需要再进行排序,只要在最终结果后排序即可
- 如果要用到字段排序,建议在外部查询select字段里使用别名(否则又要统计)
select any_value(name), max(age) m_age, class_name from (
select name, age, class_name from t_42 order by age desc limit 99999
) as t group by class_name order by m_age;
6、exists 子查询
exists子查询:代入查询,将主表(外部查询)的每一行代入到子表(子查询表)进行校验
子查询返回的结果是布尔结果
- 成功返回true
- 失败返回false
exists子查询通常是作为where条件使用
- where exists(子查询)
【例】获取所有有学生的班级信息t_46
select * from t_46 c where exists (
select c_id from t_45 where c.c_id = c_id
);7、比较方式
比较方式:在子查询中可以使用一些特定的比较方式
特定的比较方式都是基于比较符号一起使用
all:满足后面全部条件
- > all(结果集):数据要大于结果集中的全部数据
any:满足任意条件
- \= any(结果集):数据只要与结果集中的任何一个元素相等
some:满足任意条件(与any完全一样)
结果集:可以是直接的数据也可以是子查询结果(通常是列子查询)
【例】找出t_40表中与t_42表中年龄相同的信息
方案一:使用in列子查询
select * from t_40 where age in (
select distinct age from t_42
);方案二:使用exists子查询
select * from t_40 t1 where exists (
select id from t_42 where t1.age = age
);方案三:使用any或者some匹配(列子查询)
select * from t_40 where age = some(select age from t_42);