安装requests:pip install requests
GET——调用搜狗搜索
import requests
url = 'https://www.sogou.com/web?query=iie+ac'
# 在浏览器地址栏里面输入的url都是GET方式
resp = requests.get(url)
print(resp) # 200
print(resp.text) # 查看页面源代码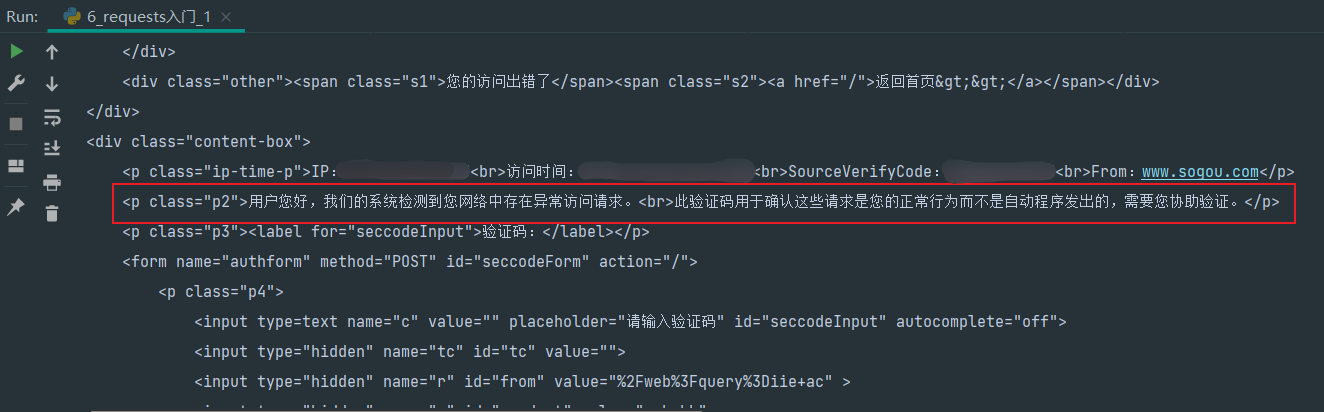
发现会被报错,需要伪装成浏览器
import requests
url = 'https://www.sogou.com/web?query=iie'
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64"
}
# 在浏览器地址栏里面输入的url都是GET方式
# 加上headers处理反爬虫
resp = requests.get(url, headers=dic)
print(resp.text)
POST——调用百度翻译
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入你要翻译的英文:")
dat = {
"kw": s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
# 将服务器返回的内容直接处理成json() => dict
print(resp.json())
豆瓣排行榜
python默认的用户标识符为:python-requests/2.25.1
import requests
# https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=0&limit=1
url = "https://movie.douban.com/j/chart/top_list"
# 重新封装参数
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 1,
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64"
}
resp = requests.get(url=url, params=param, headers=headers)
# print(resp.request.url)
print(resp.json())
# 关掉resp
resp.close()