主要内容:
- 模拟浏览器登陆
- 防盗链处理
- 代理
1. 模拟浏览器登录
-
登录 -> 得到cookie
-
带着cookie去请求到书架url -> 得到个人数据
-
可以使用session进行请求
session可以被看作为一连串的请求,在这个过程中cookie不会丢失
实战-获取17k.com小说网的个人书架
import requests
# 会话
session = requests.session()
data = {
"loginName": "***********",
"password": "*****************"
}
# 1. 登录
url1 = "https://passport.17k.com/ck/user/login"
resp1 = session.post(url1, data=data)
# 2. 获取数据
# 刚才的session中有cookie
resp2 = session.get("https://user.17k.com/ck/author/shelf?page=1&appKey=**********")
print(resp2.json())requests也可以达到相同的效果
headers = {
"Cookie": "*******"
}
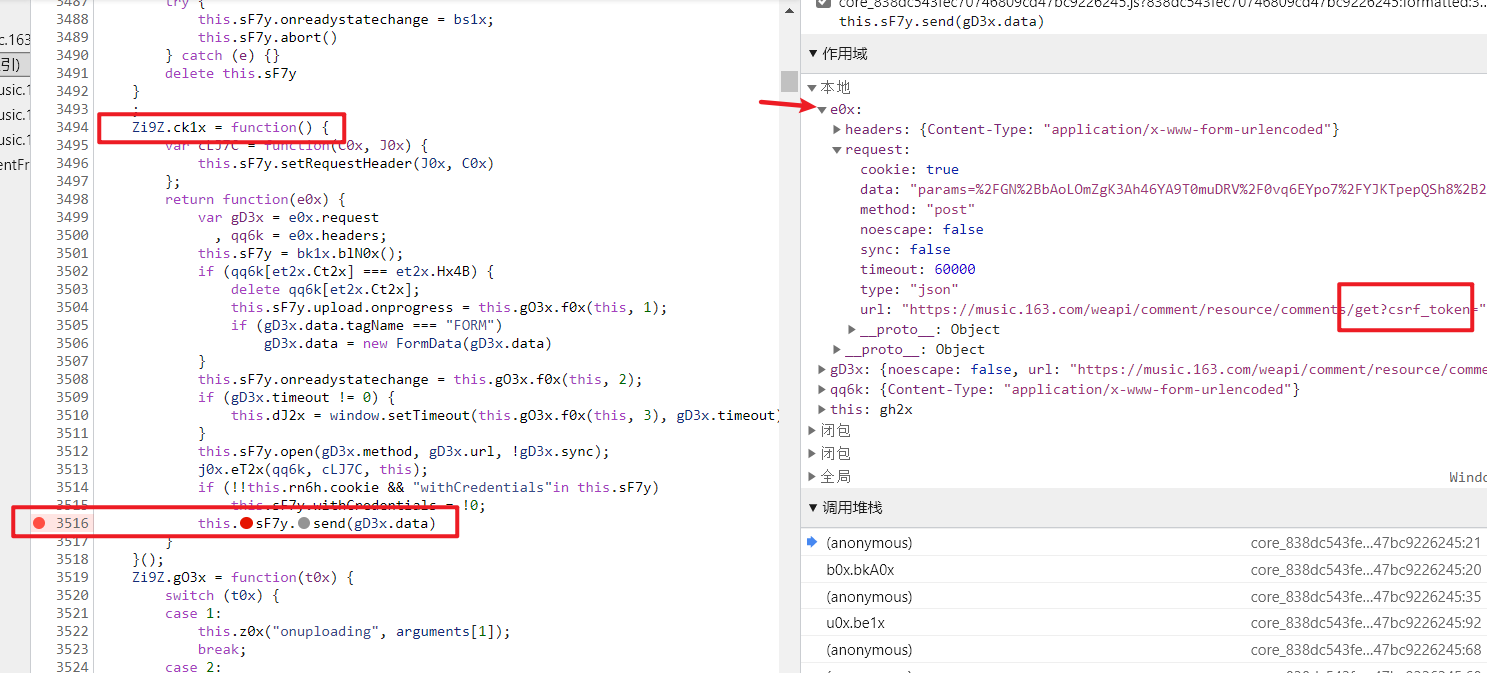
resp3 = requests.get("https://user.17k.com/ck/author/shelf?page=1&appKey=**********", headers=headers)2. 防盗链的处理
实战-爬取梨视频视频
首先,直接查看网页源代码发现是图片,点击后才有视频地址
视频地址:https://video.pearvideo.com/mp4/adshort/20210712/cont-1734862-15716746_adpkg-ad_hd.mp4
然后F12查看包的地址,发现与视频地址不一致,有部分被替换:
请求URL:https://www.pearvideo.com/videoStatus.jsp?contId=1734862&mrd=**********
视频地址:https://video.pearvideo.com/mp4/adshort/20210712/1626080467817-15716746_adpkg-ad_hd.mp4
其中,1626080467817 为 systemTime 的参数
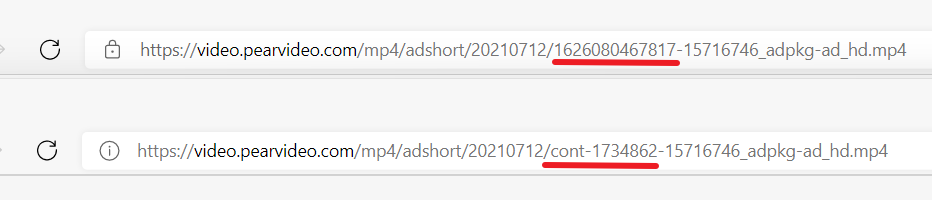
查看该视频的网址,发现替换规则:

因此,爬取过程如下:
- 拿到contID
- 拿到VideoStatus返回的json,得到srcURL
- 把srcURL中的内容进行修整
- 下载视频
import requests
# 拉取视频的网址
url = "https://www.pearvideo.com/video_1734862"
contID = url.split("_")[1]
VideoStatusURL = f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=**********"
headers = {
# 防盗链: 溯源,当前请求的上一级
"Referer": "https://www.pearvideo.com/video_1734862",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67"
}
resp = requests.get(VideoStatusURL, headers=headers)
dic = resp.json()
systemTime = dic['systemTime']
srcUrl = dic['videoInfo']['videos']['srcUrl']
srcUrl = srcUrl.replace(systemTime, f"cont-{contID}")
# 下载视频
with open("a.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
resp.close()3. 代理
import requests
proxies = {
"http": "ip:端口",
"https": "ip:端口",
"socks5": "ip:端口"
}
url = "网址"
resp = requests.get(url, proxies=proxies)
resp.encoding = 'utf-8'
resp.close()