基础函数
findall:匹配字符串中所有的符合正则的内容,返回列表
lst = re.findall(r"\d+", "我的电话是:10086,另一个是10010")
print(lst)finditer:匹配字符串中所有的内容,返回迭代器
it = re.finditer(r"\d+", "我的电话是:10086,另一个是10010")
for i in it:
print(i.group())search:找到第一个匹配到的结果,返回match对象,需要group()读取数据
s = re.search(r"\d+", "我的电话是:10086,另一个是10010")
print(s.group())match:从头开始匹配
s2 = re.match(r"\d+", "10001,我的电话是:10086,另一个是10010")
print(s2.group())预加载正则表达式
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话是:10086,另一个是10010")
for i in ret:
print(i.group())提取正则中的内容:(?P<分组名字>正则),可以从正则匹配的内容中进一步提取内容
str = """
<div class='jay'><span id='1'>asd</span></div>
<div class='jj'><span id='2'>qwe</span></div>
<div class='joy'><span id='3'>ert</span></div>
<div class='tory'><span id='4'>ghj</span></div>
<div class='sylar'><span id='5'>cvb</span></div>
"""
obj1 = re.compile(r"<div class='.*?'><span id='\d+'>\w+</span>", re.S) # re.S:让.能匹配换行符
obj2 = re.compile(r"<div class='(?P<class_name>.*?)'><span id='(?P<id>\d+)'>(?P<name>\w+)</span>", re.S)
result = obj2.finditer(str)
for it in result:
print(it.group("id"), it.group("name"))实战1—豆瓣TOP25电影信息
- 拿到页面源代码:requests
- 通过re来提取想要的有效信息:re
import requests
import re
import csv
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?)'
r' .*?<span class="rating_num" property="v:average">(?P<star>.*?)'
r'</span>.*?<span>(?P<num>.*?)人评价', re.S)
# 开始匹配
result = obj.finditer(page_content)
f = open("data/4_1.csv", mode="w")
csv_writer = csv.writer(f)
for it in result:
# print(it.group("name"), it.group("year").strip(), it.group("star"), it.group("num"))
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csv_writer.writerow(dic.values())
f.close()
resp.close()
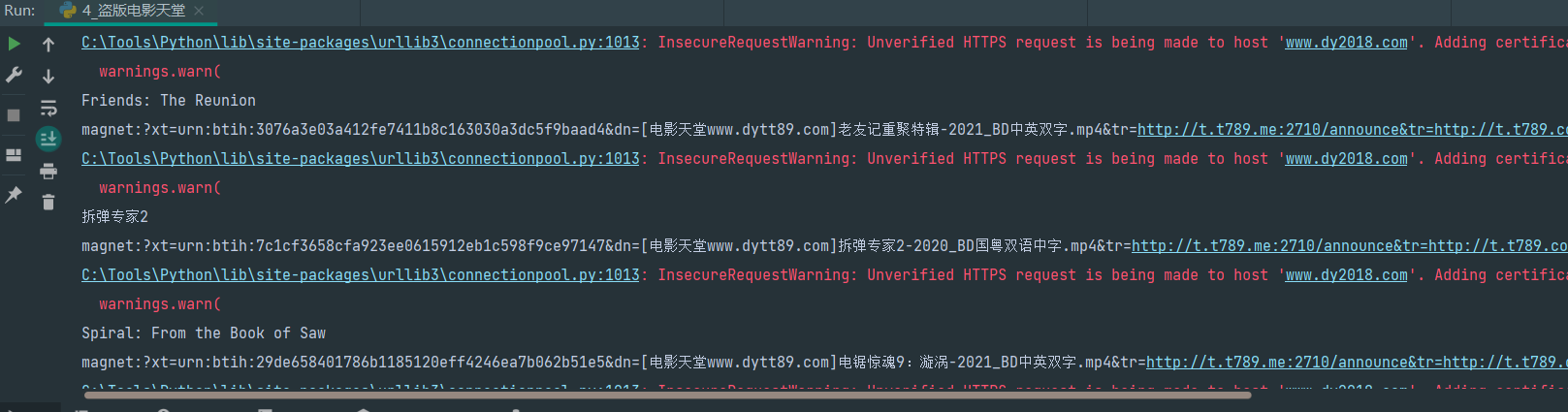
实战2-盗版电影天堂
- 定位到2021必看
- 从必看中提取到子页面的链接地址
- 请求子页面的链接地址,拿到下载地址
import requests
import re
domain = "https://www.dy2018.com/"
resp = requests.get(domain, verify=False) # verify 安全验证
resp.encoding = 'gb2312'
# print(resp.text)
# 拿到ul里面的li
obj1 = re.compile(r"2021必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
obj3 = re.compile(r'◎片 名 (?P<movie>.*?)<.*?'
r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S)
ret1 = obj1.finditer(resp.text)
child_href_list = []
for it in ret1:
ul = it.group('ul')
# 提取子页面链接
ret2 = obj2.finditer(ul)
for it2 in ret2:
# 拼接子页面:域名+子页面地址
child_href = domain + it2.group('href').strip("/")
# 保存子页面地址
child_href_list.append(child_href)
# 提取子页面内容
for href in child_href_list:
child_resp = requests.get(href, verify=False)
child_resp.encoding = 'gb2312'
ret3 = obj3.search(child_resp.text)
print(ret3.group("movie"))
print(ret3.group("download"))
resp.close()