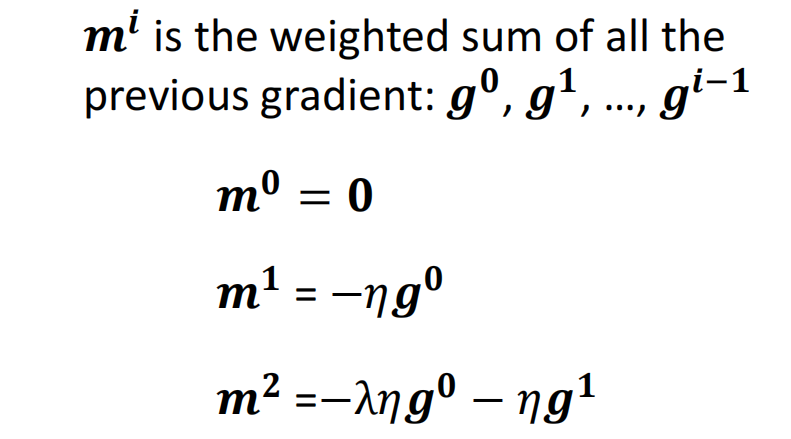Batch
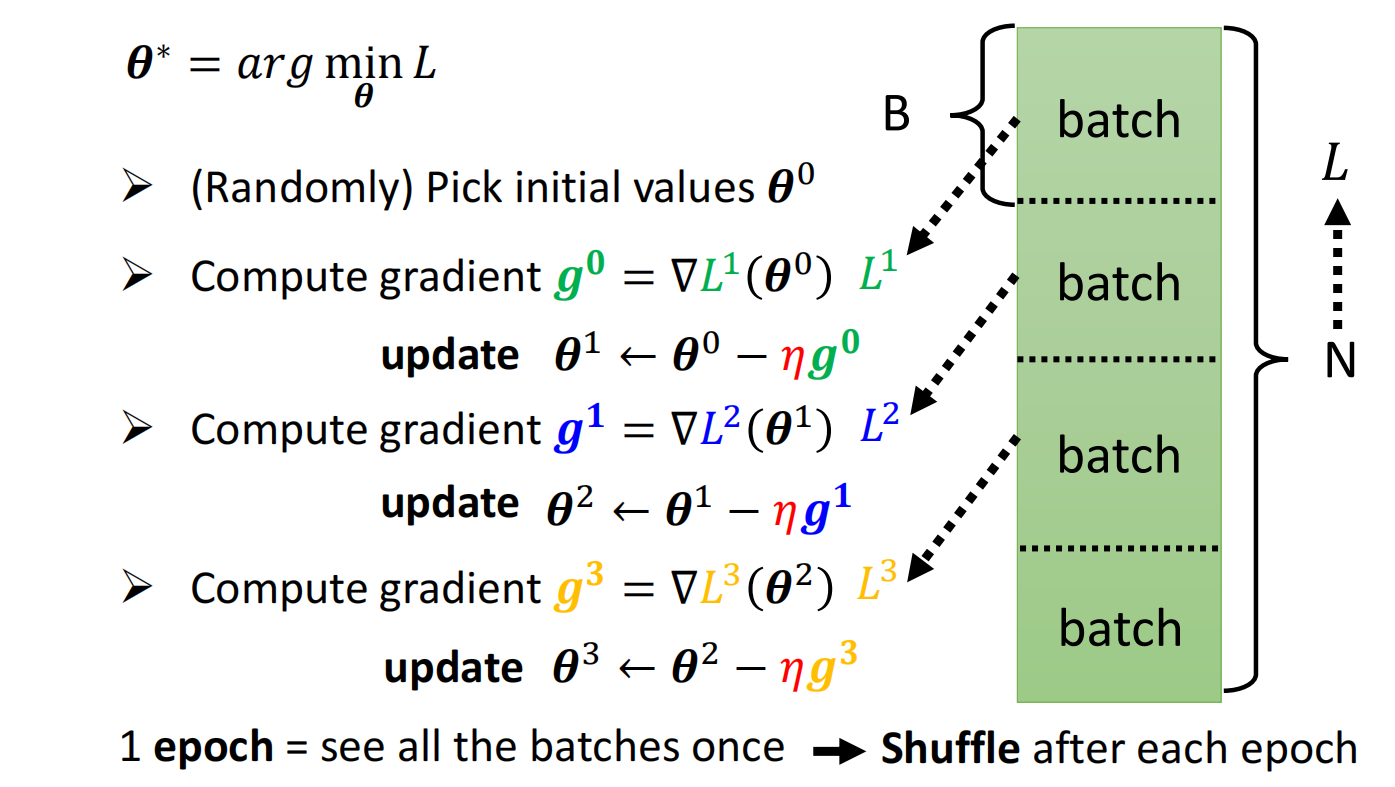
shuffle:常见做法为在每次epoch开始之前划分一次batch,每个epoch的batch都不一致,使得每个epoch都不一样
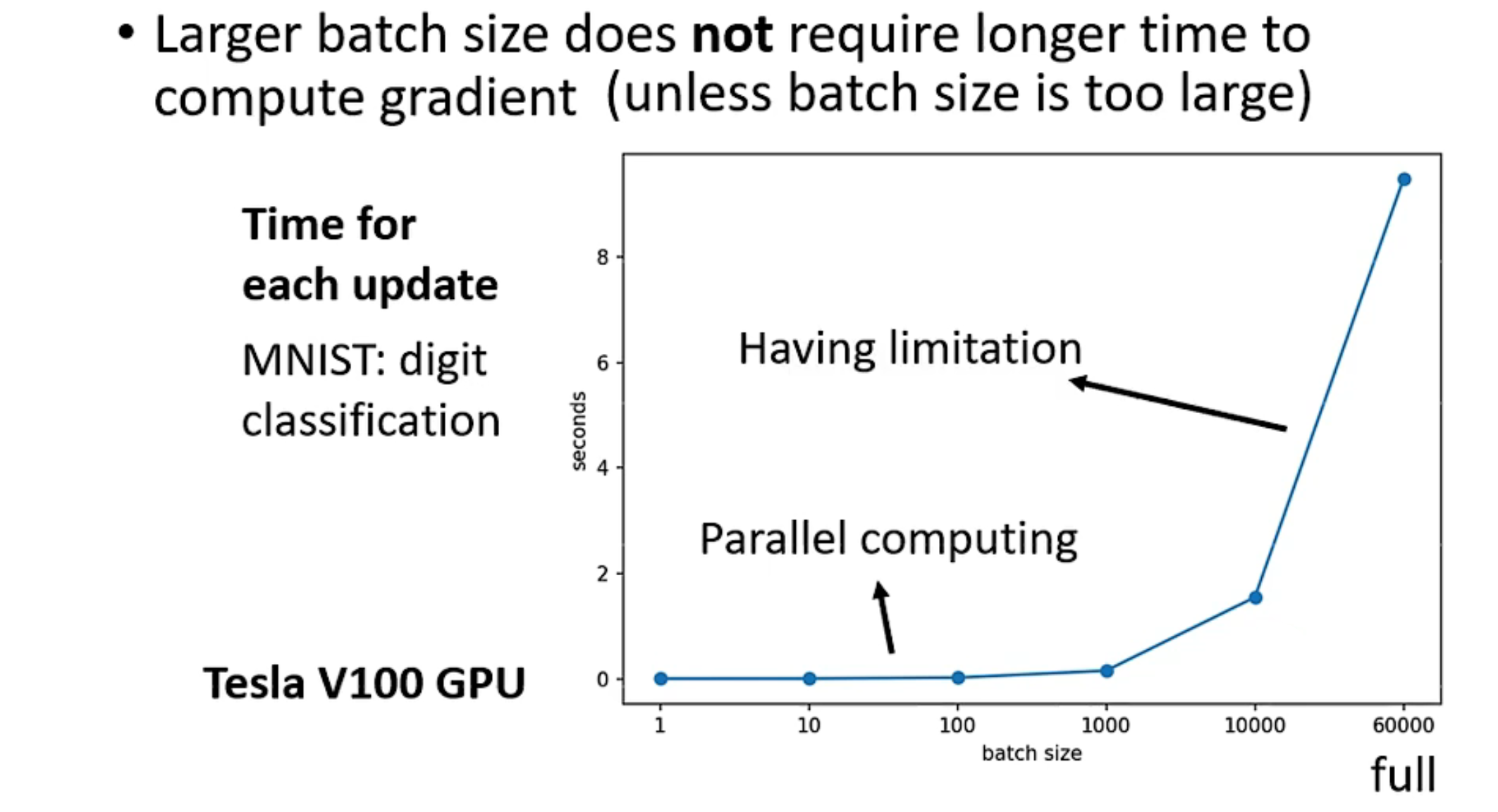
但更新参数也需要时间
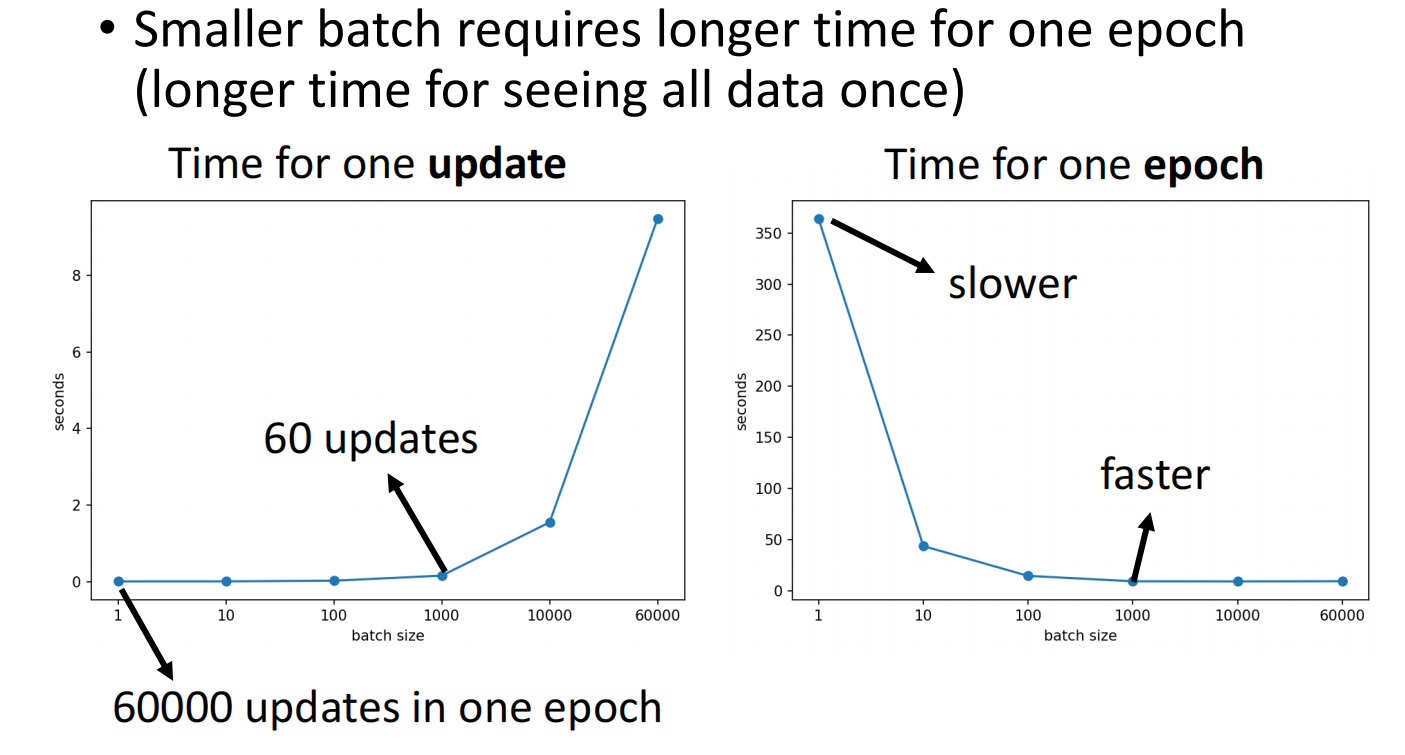
因此,batch过小其实会耗费巨量的时间,但batch过大会影响结果:
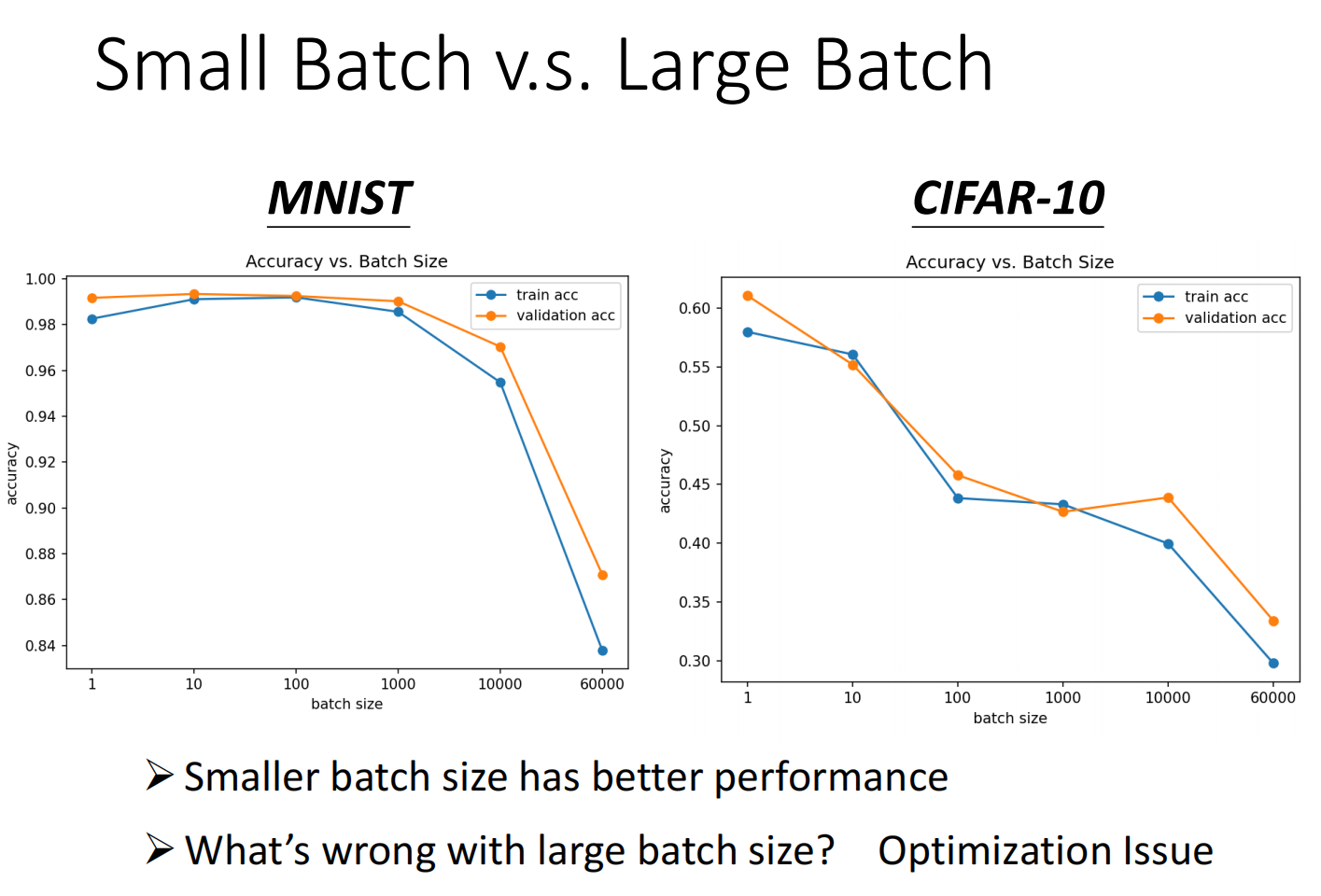
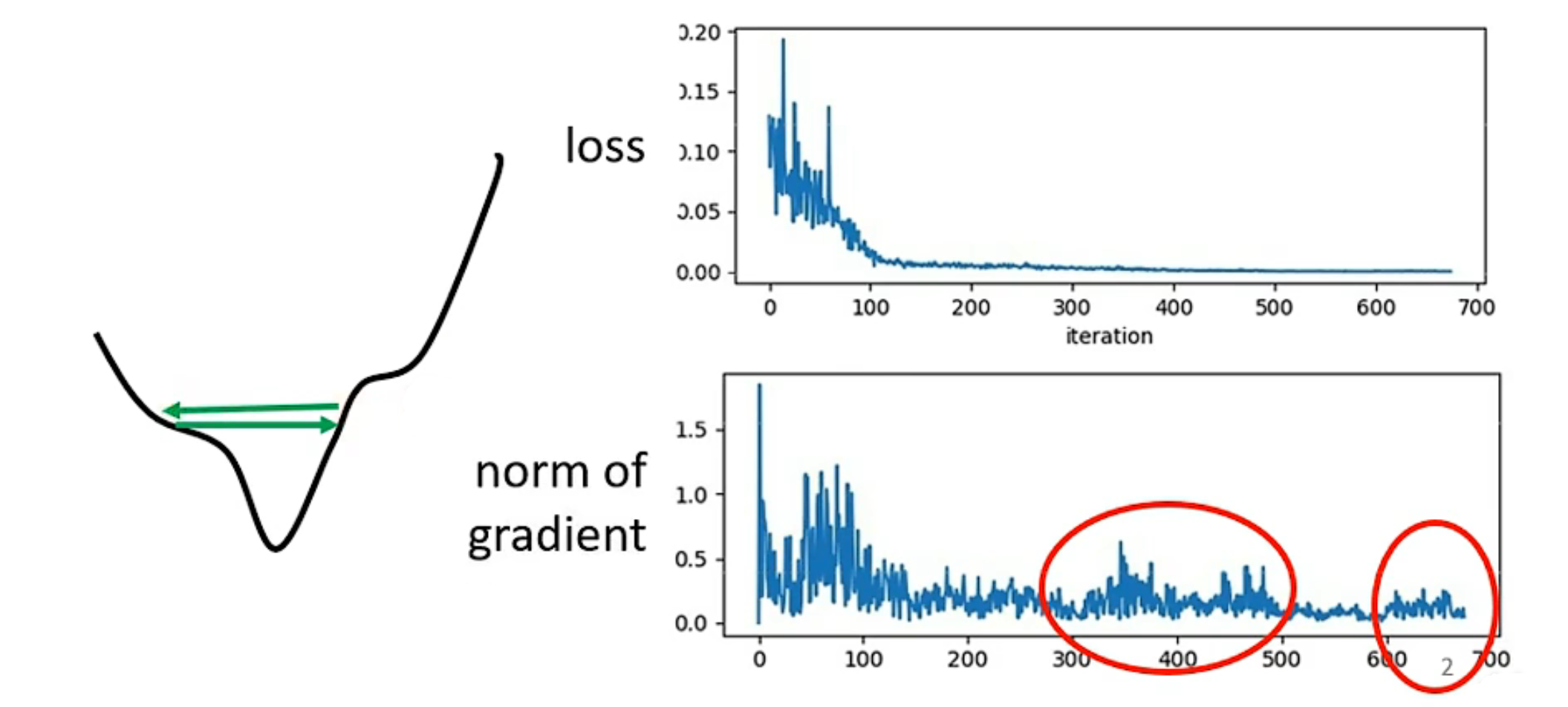
小的batch更容易跳出local minima:

即使大的batch跟小的batch在training data上的acc率一样,小batch在测试集上的效果也表现的更好:
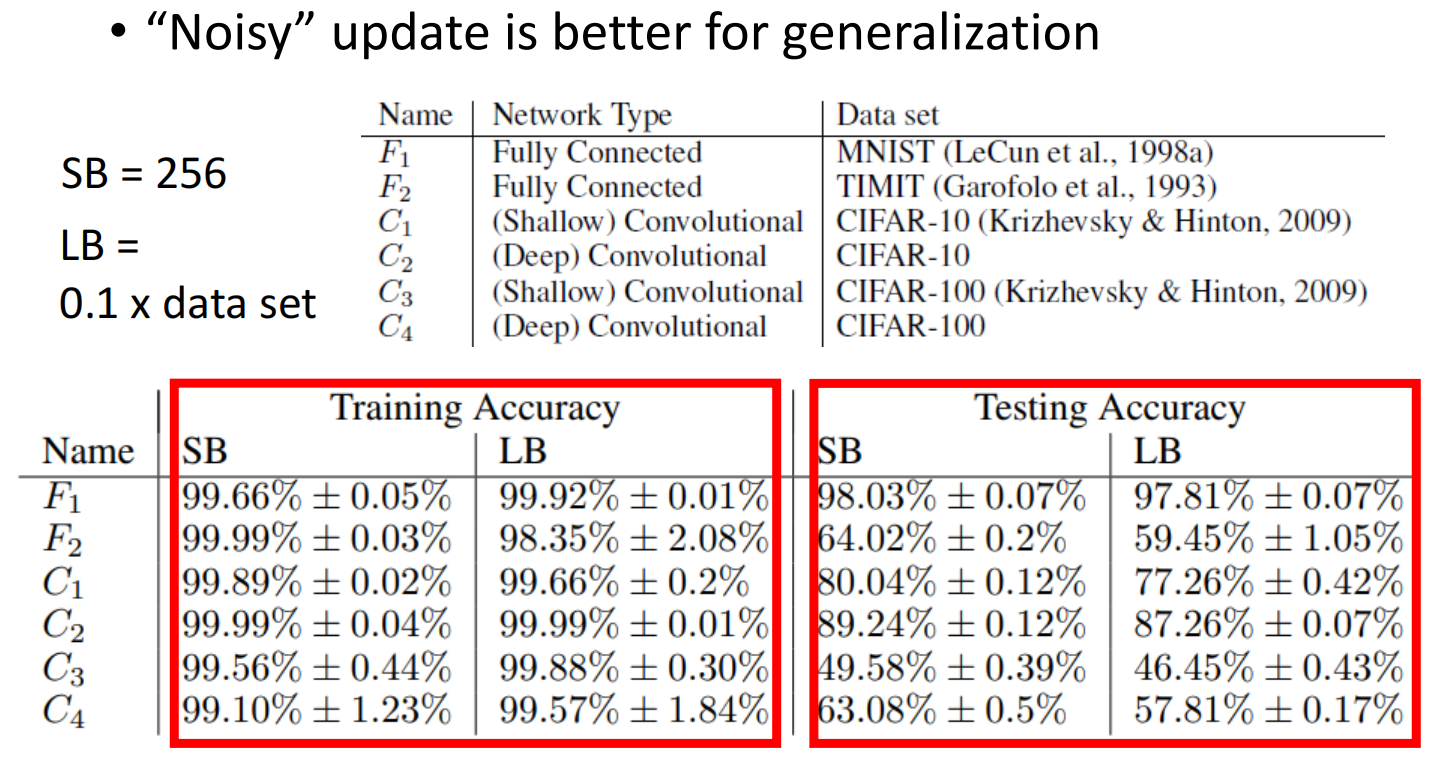
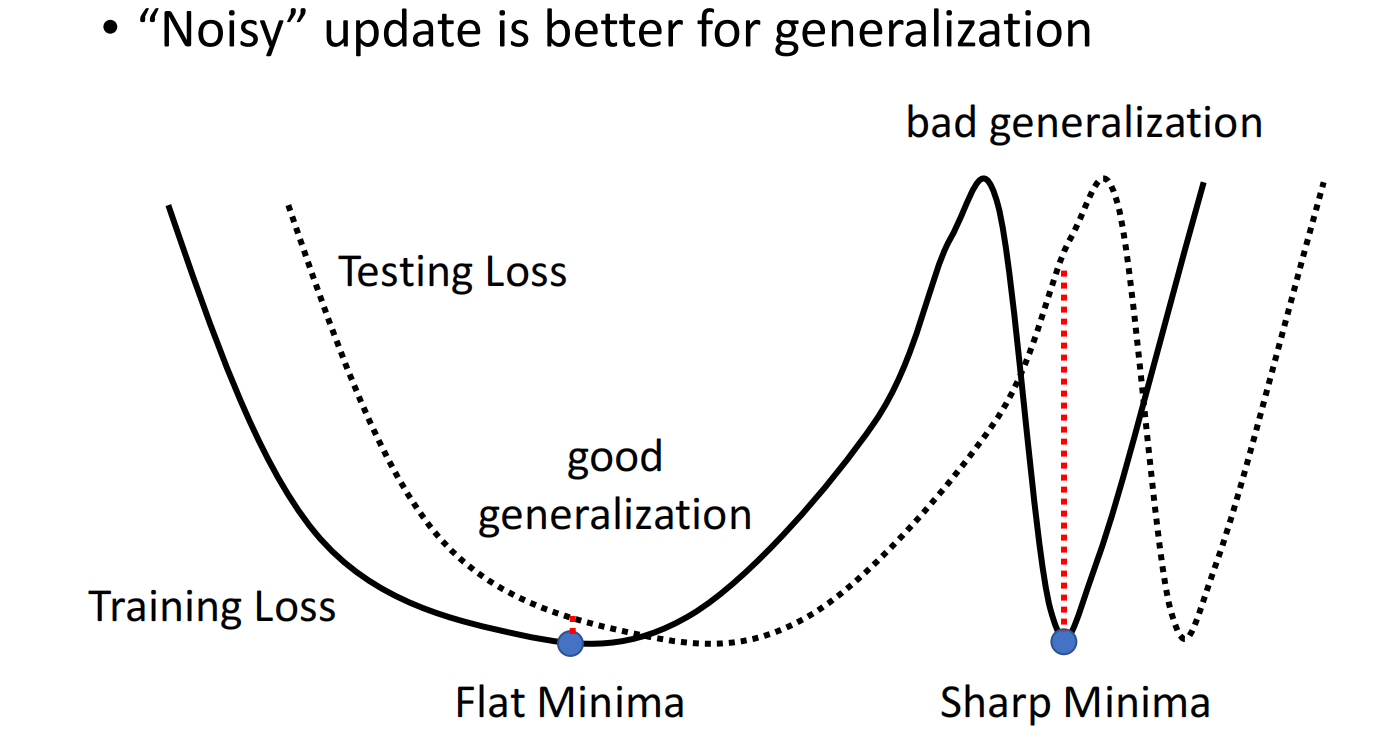
大的 batch 更倾向于进入到sharp minima
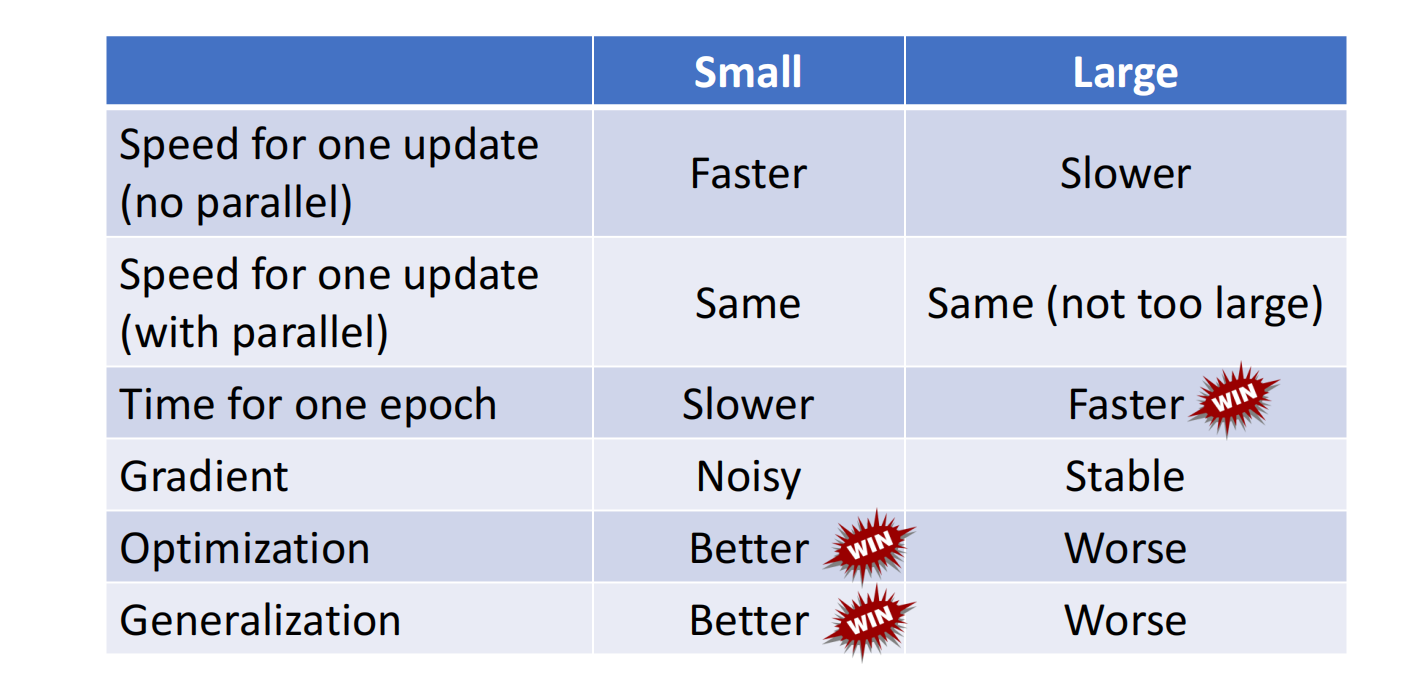
总结如下:

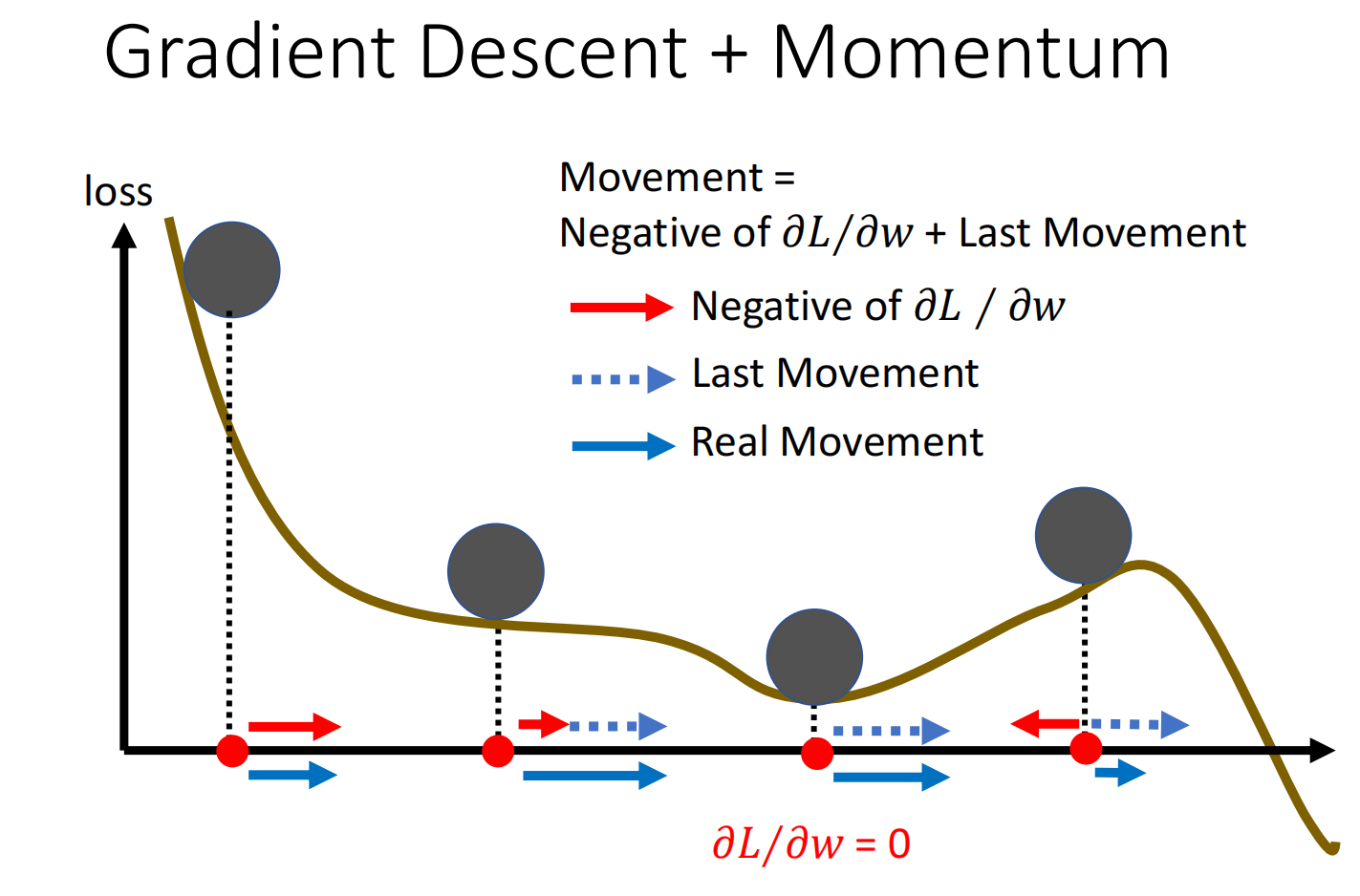
Momentum
真实世界中球会在local minima处继续向后滚动,当动能足够大到时候会冲出这个“峡谷”,那么能不能借鉴这个思路
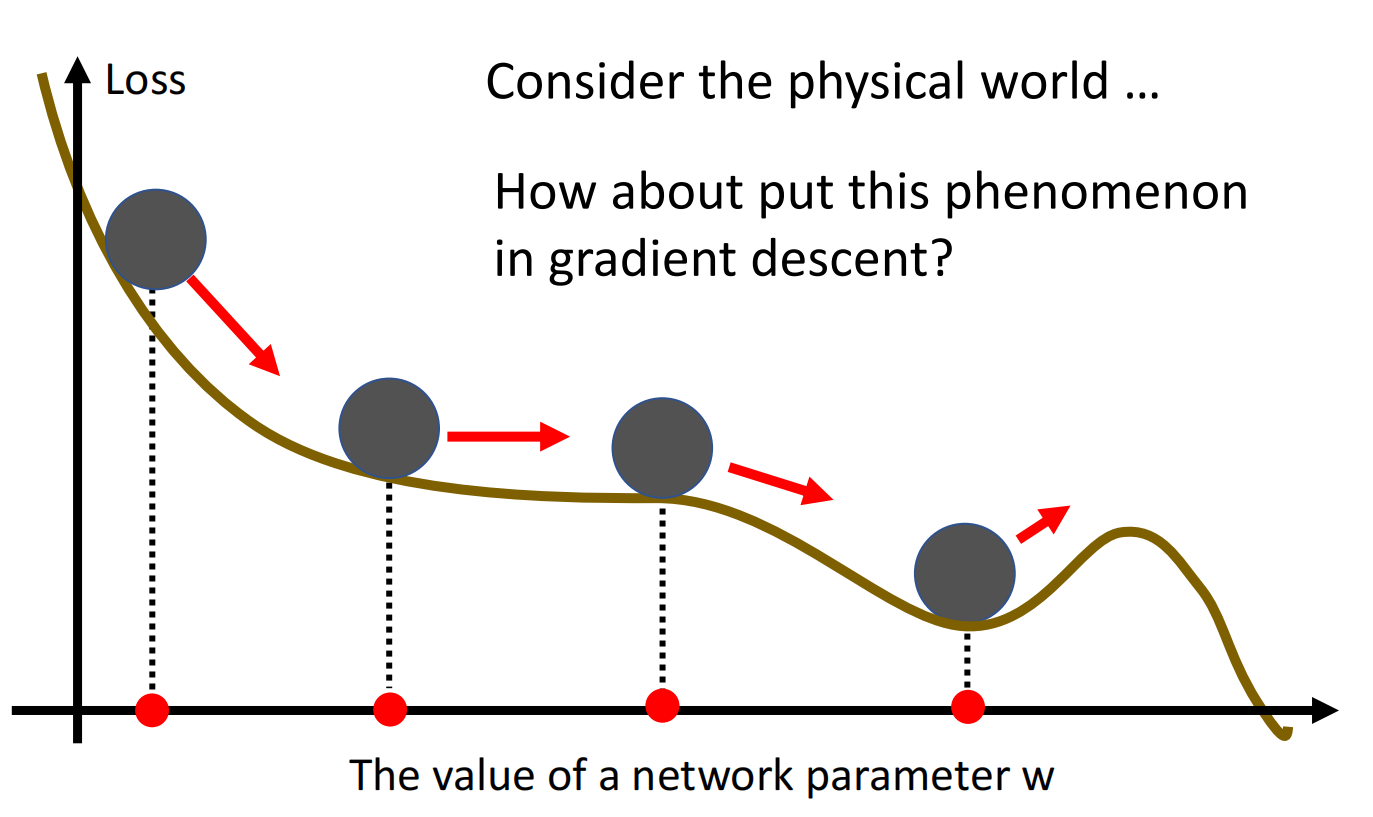
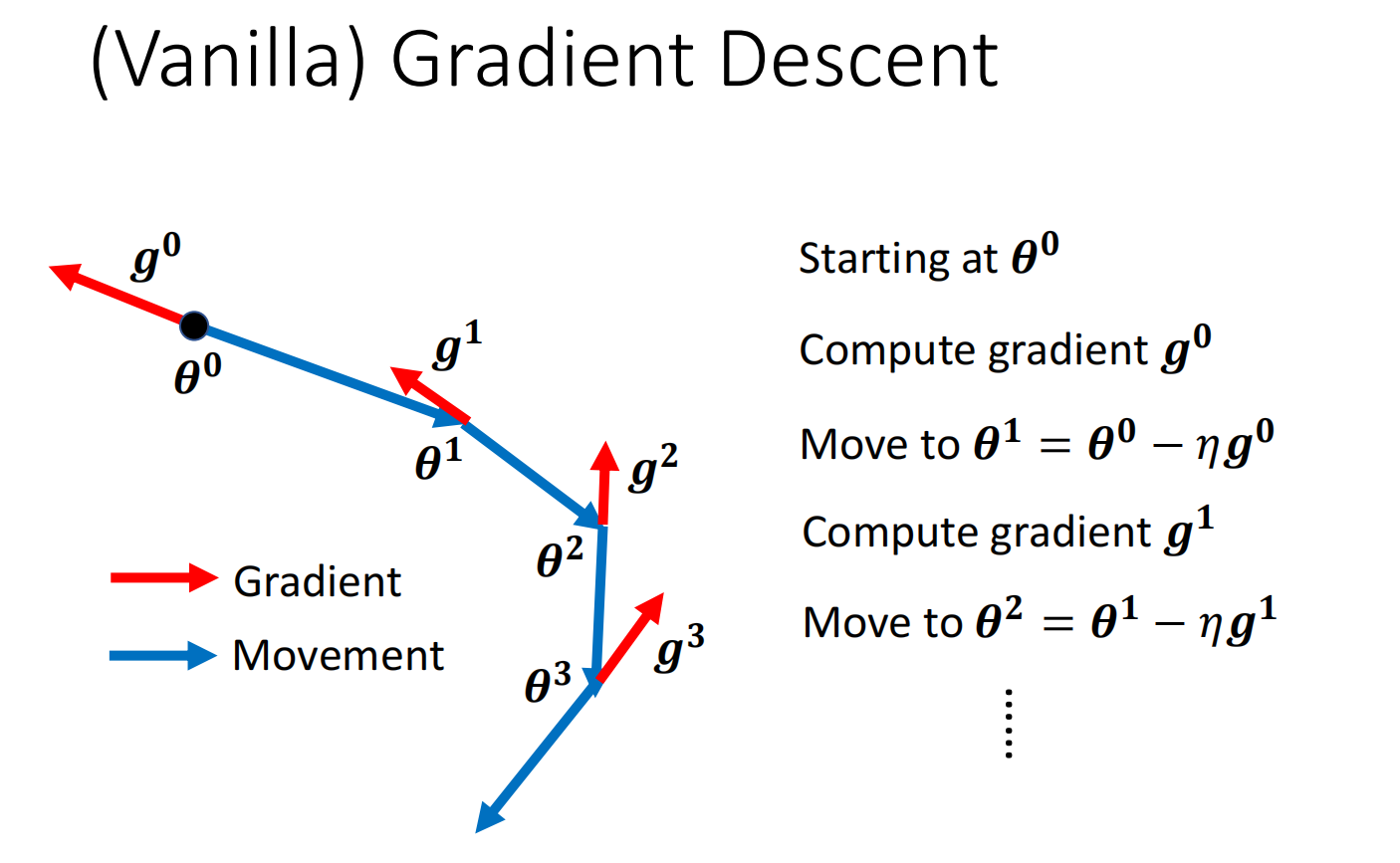
加上momentum后,移动参数的时候往gradient descent反方向+前一步的方向进行调整参数